
History of Artificial Intelligence
A discussion on the History of Artificial Intelligence, from Alan Turing to Transformers

In this post, I want to talk about the history of Artificial Intelligence, from the perceptron in the 1950’s to Large Language Models like GPT which use the Transformer architecture to provide you the latest, accurate content ever. While this has less significance from a learning perspective, I believe it will help us appreciate the efforts of so many people who have formulated research on this area — from multi-layer perceptrons to CNNs and RNNs to Transformers, quite a lot has happened in this field during the last 70 years.
The Idea of Artificial Intelligence
Well, when we think of research in computer science in 1950s, the computer used to be as large as a room — it was basically a large calculator that can do basic calculations, something like the one below, meant for research across universities in the States and Government Organizations like the NASA, who have the budgets and the need for such “calculators”.

Even though they might be good at doing relatively complicated calculations, people still were dependent on mathematicians to predict values for solving their problems. From this, people thought of machines which could ‘think’ and solve their issues as a research topic, the first being then eminent computer scientist, Alan Turing.
Alan Turing and the Imitation Game
The idea of Artificial Intelligence was first brought forth by and he basically starts off with his seminal paper in 1950, called COMPUTING MACHINERY AND INTELLIGENCE, where he proposes an “imitation game” where an interrogator (the user) is asked to identify the liar (machine) from the truth sayer(may be a set of facts, or static information which you do not believe in straight away, but is not a machine). The user’s goal here is to identify the machine out of the two, whereas the machine’s goal is to manipulate the user into believing that it is human.

One of his core propositions in the paper suggest that thinking machines are like children (he calls it a child machine) which gets a education (data) and the process of education being faster than evolution(lol, but this is what training a model inherently is), passing through “natural selection“ (insert any model optimization method like hyper parameter tuning), where “punishments and rewards” are given to the machine for a wrong and right response respectively (insert reinforcement learning). He also states that these punishments and rewards can’t be the sole technique to drive thinking in the machine, that they also need enough input to make sense of the “teacher’s” queries ( which he calls as “unemotional” channels").
Other propositions based off this state that the “teacher” might not really know what is going on in the learner’s mind (he states these models are blackboxes), although he can predict the child’s response if he is well “educated” (yeah a trained model will give you good responses, duh).
Also it is stated that this machines benefit from having a random element in them (insert random initialization technique). His reasoning is that there are certainly many satisfactory solutions to the “teacher’s” query, which can take a lot more time when going through it in a systematic way, whereas randomly picking up for the answer leads us to pick a “satisfactory” answer to the query.
In summary, this is what his seminal paper has to say about “thinking machines”, which in a way led to coining of the term “artificial intelligence” by Professor John McCarthy at the Dartmouth Conference.
Dartmouth Conference
From there in 1956 at the Dartmouth Conference, he proposed studies with 10 people on Artificial Intelligence. Some of the other members in the proposal include:
Claude E. Shannon (Also called as the Father of Information Theory, Claude is literally named after him!)
Marvin L. Minsky (Computer Scientist who Cofounded MIT’s AI Lab, which is now the CSAIL.
Nathaniel Rochester (Chief Architect of the first scientific computer, IBM 701)
They considered the following aspects as critical to solving the “thinking machine” problem:
Automatic Computers: Necessity of programming techniques to perform actions simulating the machine “thinking”
Rule based structure to understand natural language was not possible. So need constructs to understand natural language.
Neuron Nets: By taking notes from neurons connecting to the brain upon which experiments were conducted, from which came the concept of Perceptron.
Self-Improvment: An AI system learns from self-improvment on the problems it learns from.
Randomness and Creativity: It is considered to have controlled randomness to train the AI make an educated guess, over an inefficient orderly thinking.
Perceptron
Inspired by the proposal, Frank Rosenblatt proposed for building a AI System using a “Perceptron” in the paper THE PERCEPTRON: A PROBABILISTIC MODEL FOR INFORMATION STORAGE AND ORGANIZATION IN THE BRAIN.
His idea of perceptron being a singular unit (like the cell being a singular unit of an organ) to understand and mimic the capabilities of perception in higher organisms, by answering the three fundamental questions:
How is information about the physical world sensed, or detected, by the biological system?
In what form is information stored, or remembered?
How does information contained in storage, or in memory, influence recognition and behavior?
He has two working ideals for answering the second question. One is about storing information in “coded representations” with a sort of one-to-one mapping between the neurons, meaning the response can be retraced back from the representations within the network of neurons(which is indeed false) . His other ideal states that the neuron only stores the preference to a particular response across the “neural network”. It is also stated as a proposal that in recognition, the pathways which were used/created would be used again to gain the “understanding” of new stimuli.
For example, you could take the example of drinking tea, If you are used to drinking your coffee hot, you already know that since it is hot, you would sip it slowly. The same way even if tea is something entirely new to you, the fact that you are trying to drink it hot, stimulates the same response to sip tea slowly — just like you did for coffee earlier.
These responses to the questions 2 and 3 have brought forth the idea of what he called the perceptron, a far simpler representation for a “thinking machine”(he does not call it directly, but this is what we are using neural networks with) removing the complexities of biological neurons, built on the ideas of probability rather than symbolic logic.
The idea of the perceptron laid foundation for our standard neural networks used in deep learning.
Problems with the Perceptron Model
One of the core issues observed with the Perceptron model, is that the model only updates the “association” and “response” layers only as give in the diagram below — given the ideas surrounding at the time, he took inspiration from the human eye.
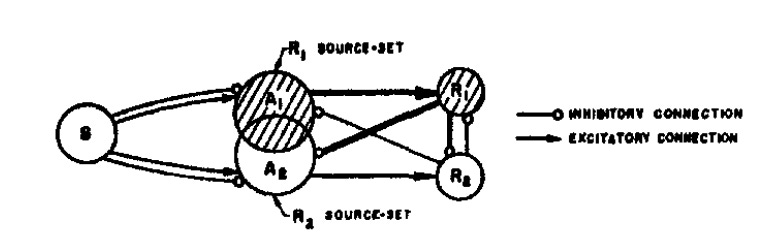
Which causes them to identify only linearly separable patterns (there is no non-linearity in the system, which is why you need ACTIVATION FUNCTIONS in general, even though a step function is used at the end for binary classification). These limitations were suggested later in 1969 in the book called “Perceptrons” which greatly decreased interest in the usage of neural models to solve artificial intelligence problems.
Multi-layer Perceptron
To solve the shortcomings in the single layer perceptron, a multi-layer perceptron architecture was suggested.( Note that this architecture comes under the class of feedforward neural networks, since they move forward towards a result from the ‘feed’ of data).
A Multi-layer Perceptron is a highly modified version of the perceptron, where you add more ‘layers’ and activations to understand the inputs given. The ‘non-linearity’ is present at every layer (these are your activation functions).
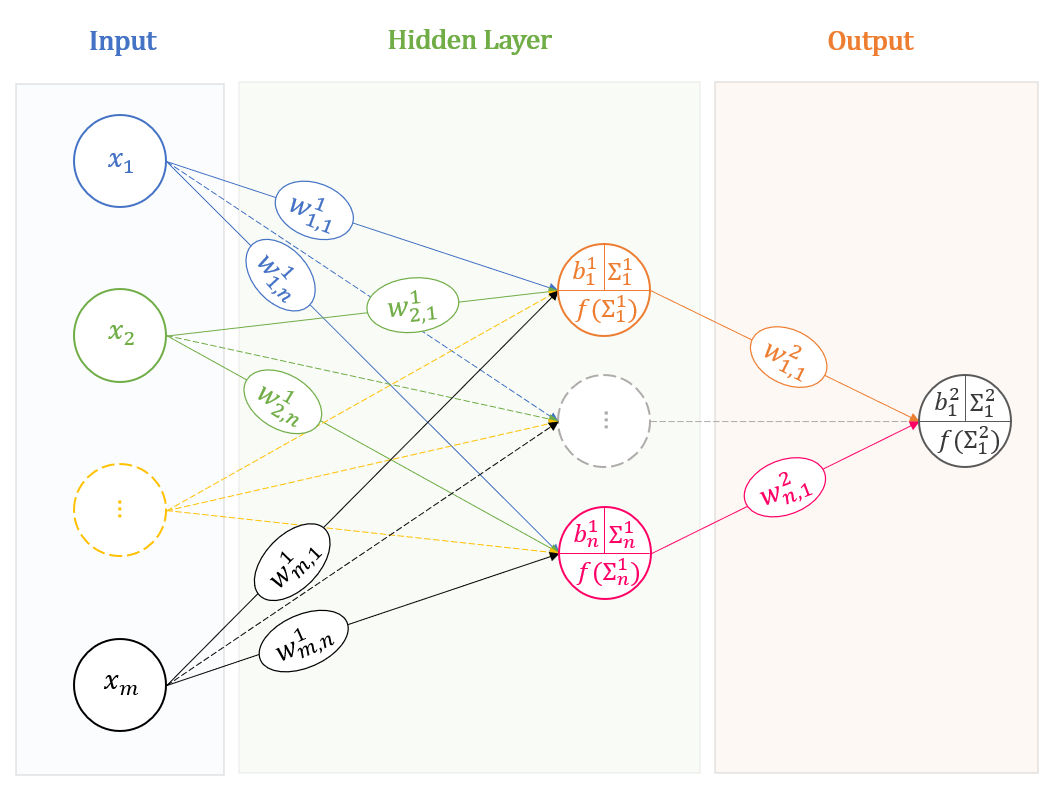
Now the activation functions can be anything from step, sigmoid, tanh to even polynomial functions (Such neural networks are called polynomial neural networks, even though they are not that popular anymore since they are computationally expensive).
AI Winter
So basically the core fight for AI was between neural systems and rule-based symbolic AI systems. One based off the representational knowledge of data we train upon, whereas the other replicated rules to make haste. And one of the core issues people faced with neural networks (MLPs) were that they were incredibly HARD to train them with the computation levels of 1960s. This is where we see the First Winter of AI in the 1970s to mid-1980s.
The issue was always about the lack of computation capabilities along with a lack of performance of the models.
The second AI winter came during the end of 1980s to 2000s. There was a great interest back in building expert systems with AI for business use cases. These systems used to be developed in Lisp during the early 80’s. What indeed shocks me a bit is that despite backpropagation being modernized and implemented to MLPs, people were unable to train it for its intended use case of expert systems.
The problem which these systems inherently faced come under what people call the “qualification problem”. It can be described with an example as followed:
“Suppose a company wants to build a car for a certain demographic. Now if the company wants to taste success with this project, they can make sure they have a proper understanding of the demographic’s needs, affordability and the car should be safe quick and cheap to build etc, etc.
Now in this instance, if you want to be successful, you would want to make sure you sort out every issue you know or at least make sure you know enough to be successful. The qualification problem states that trying to know literally EVERYTHING is just not possible for the intended outcome.”
All expert systems were not able to solve this problem, alongside AI based expert systems were being really expensive to compute and maintain. Cheaper alternatives/architectures and systems from Apple and IBM successfully cemented these circumstances for the rest of the 90s for majority of businesses, thereby also causing a lot of AI businesses to go bankrupt of change their business focus.
Rise from ashes?
The rise of AI happened in the late 90’s to 2000’s with the development of new domains like Machine Learning and Deep Learning, with ever improving compute. For example, the paper on CNN by Yann LeCun, Yoshua Bengio, Léon Bottou and Patrick Haffner came in 1998, explaining the use of Gradient-based Learning with back propagation to classify handwritten digits. Later on, a lot of research was actively being conducted in the field of AI, with a greater resurgence in the field post improved confidence in techniques and compute ability, this slowly brought in increased investments in AI research, although the weird thing being that people earlier were so skeptical of AI, the researchers themselves refrained to publish the papers in the name of ‘Artificial Intelligence’ (example: the CNN paper itself!)
Today (2016-2022?)
The major turning point of AI from being more research oriented - limited business application (they were quite a lot of them linear regression algorithms in banking) like regression, SVMs to crazy applications that we see today are primarily dues to the advances in parallel computation with NVIDIA’s GPUs and OpenAI utilizing them, making them as the first mover and a successful tech giant in this field, with currently around 400 weekly active users.
GPUs although were primarily used for Graphics Processing, the later versions starting from 2006 were built upon a programming model called CUDA, primarily for general purpose programming tasks (insert machine learning, deep learning).
Summary
Well this has been a long post, but to summarize it all we can see that it all started with one man interpreting what a ‘thinking machine’ would look like, to ideating how they should think by taking inspiration from the literal eye, to the most exciting period of our generation with LLMs like GPT-4o and other applications like Midjourney, it all started somewhere simple, but it with the consistent efforts of many, this became our reality.
P.S:
(While I could go on to discuss more on what these papers entail, I would suggest you read Turing’s paper nonetheless, it is fun indeed). Also do watch this video about Turing Machines, which form the basis of computing.